
Bayesian Probabilistic Models for Classification
12 min
Tuesday, October 22, 2024
In machine learning, classification is one of the most common tasks, where the goal is to assign a label to an input from a set of possible categories. While binary classification, where there are only two labels (e.g., spam vs. not spam), is well understood, real-world problems often involve more than two classes—this is where multi-class classification comes into play. In this post, we’ll explore various techniques and algorithms used to solve multi-class classification problems effectively.
Multi-class classification involves assigning an input to one of several distinct classes. For instance, given an image of an animal, the task may be to classify it as either a dog, cat, horse, or bird. The key challenge here is to handle more than two classes, which introduces additional complexity compared to binary classification.
There are two main ways of handling multi-class classification:
Let’s consider the classic Iris dataset that contains three classes of iris species: setosa, versicolor, virginica. We will use this dataset to demonstrate different multi-class classification techniques in python.
import pandas as pd
import numpy as np
from sklearn.datasets import load_iris
import seaborn as sns
import matplotlib.pyplot as plt
# set the background color
sns.set(rc={'axes.facecolor': '#f4f4f4', 'figure.facecolor':'#f4f4f4'})
iris = load_iris()
df = pd.DataFrame(data = iris.data, columns = iris.feature_names)
df['species'] = iris.target
df['species'] = df['species'].map({0: 'setosa', 1: 'versicolor', 2: 'virginica'})
print(df.head())
sns.pairplot(df, hue='species', height=1.8, aspect=0.99)
plt.show() sepal length (cm) sepal width (cm) petal length (cm) petal width (cm) \
0 5.1 3.5 1.4 0.2
1 4.9 3.0 1.4 0.2
2 4.7 3.2 1.3 0.2
3 4.6 3.1 1.5 0.2
4 5.0 3.6 1.4 0.2
species
0 setosa
1 setosa
2 setosa
3 setosa
4 setosa 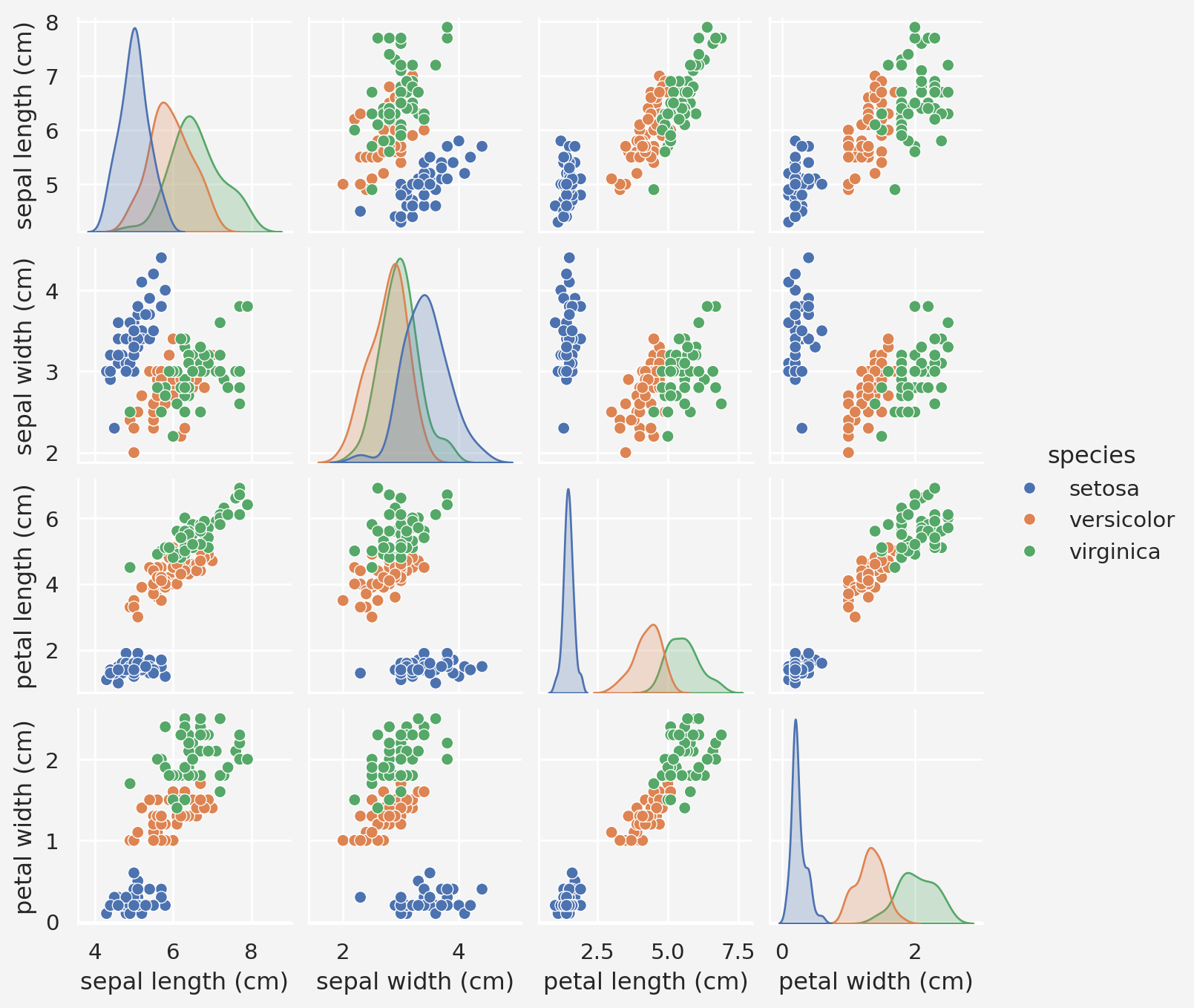
These are algorithms that can directly handle multiple classes in their formulation:
a. Decision Trees (See more here)
Decision Trees can naturally handle multi-class classification tasks. At each split, the tree decides on a rule that best separates the data into groups. The terminal nodes (leaves) represent the class predictions.
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
X_train, X_test, y_train, y_test = train_test_split(
iris.data,
iris.target,
test_size=0.3,
random_state=123
)
clf = DecisionTreeClassifier()
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(classification_report(y_test, y_pred, target_names=iris.target_names)) precision recall f1-score support
setosa 1.00 1.00 1.00 18
versicolor 0.83 1.00 0.91 10
virginica 1.00 0.88 0.94 17
accuracy 0.96 45
macro avg 0.94 0.96 0.95 45
weighted avg 0.96 0.96 0.96 45
b. Random Forests (See more here)
Random Forests are ensembles of decision trees and can also naturally handle multi-class classification. They aggregate the predictions from multiple trees to make a final classification decision.
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier()
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(classification_report(y_test, y_pred, target_names=iris.target_names)) precision recall f1-score support
setosa 1.00 1.00 1.00 18
versicolor 0.83 1.00 0.91 10
virginica 1.00 0.88 0.94 17
accuracy 0.96 45
macro avg 0.94 0.96 0.95 45
weighted avg 0.96 0.96 0.96 45
c. Naive Bayes (See more here)
Naive Bayes is a probabilistic classifier based on Bayes’ theorem, assuming that the features are independent. The algorithm calculates the probability of each class and predicts the one with the highest probability.
from sklearn.naive_bayes import MultinomialNB
clf = MultinomialNB()
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(classification_report(y_test, y_pred, target_names=iris.target_names)) precision recall f1-score support
setosa 1.00 1.00 1.00 18
versicolor 0.37 1.00 0.54 10
virginica 0.00 0.00 0.00 17
accuracy 0.62 45
macro avg 0.46 0.67 0.51 45
weighted avg 0.48 0.62 0.52 45
/opt/hostedtoolcache/Python/3.10.16/x64/lib/python3.10/site-packages/sklearn/metrics/_classification.py:1517: UndefinedMetricWarning:
Precision is ill-defined and being set to 0.0 in labels with no predicted samples. Use `zero_division` parameter to control this behavior.
/opt/hostedtoolcache/Python/3.10.16/x64/lib/python3.10/site-packages/sklearn/metrics/_classification.py:1517: UndefinedMetricWarning:
Precision is ill-defined and being set to 0.0 in labels with no predicted samples. Use `zero_division` parameter to control this behavior.
/opt/hostedtoolcache/Python/3.10.16/x64/lib/python3.10/site-packages/sklearn/metrics/_classification.py:1517: UndefinedMetricWarning:
Precision is ill-defined and being set to 0.0 in labels with no predicted samples. Use `zero_division` parameter to control this behavior.
d. K-Nearest Neighbors (KNN) (See more here)
KNN is a non-parametric algorithm that classifies a data point based on the majority class of its k-nearest neighbors. It can handle multi-class problems by considering the most frequent class among the neighbors.
from sklearn.neighbors import KNeighborsClassifier
clf = KNeighborsClassifier(n_neighbors=5)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(classification_report(y_test, y_pred, target_names=iris.target_names)) precision recall f1-score support
setosa 1.00 1.00 1.00 18
versicolor 1.00 0.90 0.95 10
virginica 0.94 1.00 0.97 17
accuracy 0.98 45
macro avg 0.98 0.97 0.97 45
weighted avg 0.98 0.98 0.98 45
Some algorithms are inherently binary, but they can be adapted to handle multiple classes using strategies like:
a. One-vs-Rest (OvR)
This technique involves training one classifier per class. Each classifier is trained to distinguish one class from the rest (i.e., treat it as a binary classification problem). During prediction, the classifier that outputs the highest confidence score assigns the label.
Example with Logistic Regression
from sklearn.linear_model import LogisticRegression
from sklearn.multiclass import OneVsRestClassifier
clf = OneVsRestClassifier(LogisticRegression())
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(classification_report(y_test, y_pred, target_names=iris.target_names)) precision recall f1-score support
setosa 1.00 1.00 1.00 18
versicolor 0.83 1.00 0.91 10
virginica 1.00 0.88 0.94 17
accuracy 0.96 45
macro avg 0.94 0.96 0.95 45
weighted avg 0.96 0.96 0.96 45
b. One-vs-One (OvO)
This strategy involves training a binary classifier for every possible pair of classes. For a dataset with \(n\) classes, \(\frac{n(n-1)}{2}\) classifiers are trained. The class with the most “votes” from the classifiers is the predicted label.
Example with support vector classifier
from sklearn.multiclass import OneVsOneClassifier
from sklearn.svm import SVC
clf = OneVsOneClassifier(SVC())
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(classification_report(y_test, y_pred, target_names=iris.target_names)) precision recall f1-score support
setosa 1.00 1.00 1.00 18
versicolor 0.71 1.00 0.83 10
virginica 1.00 0.76 0.87 17
accuracy 0.91 45
macro avg 0.90 0.92 0.90 45
weighted avg 0.94 0.91 0.91 45
a. Softmax Regression
In neural networks, multi-class classification is typically handled using the softmax function in the output layer. Softmax converts raw output scores (logits) into probabilities for each class, ensuring they sum to 1. The class with the highest probability is chosen as the predicted class.
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Input
from tensorflow.keras.optimizers import SGD
input_layer = Input(shape = (X_train.shape[1],))
model = Sequential([
input_layer,
Dense(64, activation = 'relu'),
Dense(64, activation = 'relu'),
Dense(3, activation = 'softmax')
])
optimizer = SGD(learning_rate=0.001)
model.compile(
optimizer = optimizer,
loss = 'sparse_categorical_crossentropy',
metrics = ['accuracy']
)
model.fit(X_train, y_train, epochs = 50, batch_size = 10, verbose = 0)
test_loss, accuracy = model.evaluate(X_test, y_test)
print(f'Test Accuracy: {accuracy}') 2025-01-22 04:20:24.935203: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:477] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
E0000 00:00:1737519624.948735 15298 cuda_dnn.cc:8310] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered
E0000 00:00:1737519624.953181 15298 cuda_blas.cc:1418] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
2025-01-22 04:20:24.969353: I tensorflow/core/platform/cpu_feature_guard.cc:210] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: AVX2 FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
2025-01-22 04:20:26.606615: E external/local_xla/xla/stream_executor/cuda/cuda_driver.cc:152] failed call to cuInit: INTERNAL: CUDA error: Failed call to cuInit: UNKNOWN ERROR (303)1/2 ━━━━━━━━━━━━━━━━━━━━ 0s 88ms/step - accuracy: 0.8750 - loss: 0.54282/2 ━━━━━━━━━━━━━━━━━━━━ 0s 15ms/step - accuracy: 0.8991 - loss: 0.5435
Test Accuracy: 0.9111111164093018Training and Validation loss
X_train, X_val, y_train, y_val = train_test_split(
X_train, y_train, test_size=0.10, random_state=123,
stratify=y_train
)
history = model.fit(
X_train, y_train, epochs = 150,
batch_size = 10, verbose = 0,
validation_data = (X_val, y_val)
)
train_loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(train_loss)+1)
plt.plot(epochs, train_loss, 'b-', label = "Training Loss")
plt.plot(epochs, val_loss, 'r-', label = "Validation loss")
plt.title('Training and Validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()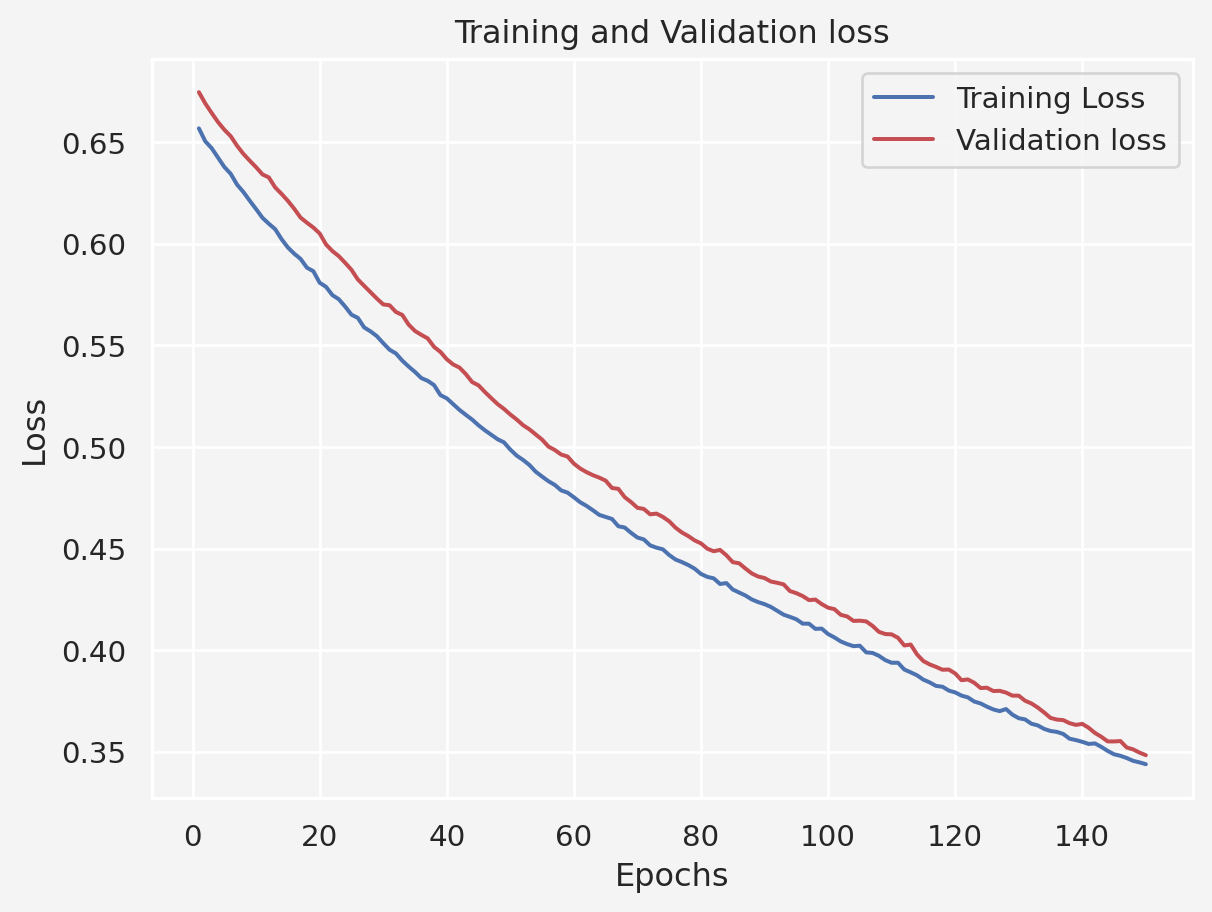
b. Convolutional Neural Networks (CNNs)
For image classification tasks, CNNs are widely used. CNNs automatically learn spatial hierarchies of features, making them highly effective for tasks like object recognition in images.
Evaluating multi-class classification models requires more nuanced metrics than binary classification. Some common evaluation metrics include:
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
sns.heatmap(
cm, annot=True, fmt='d', cmap='Blues',
xticklabels=iris.target_names,
yticklabels=iris.target_names
)
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.show()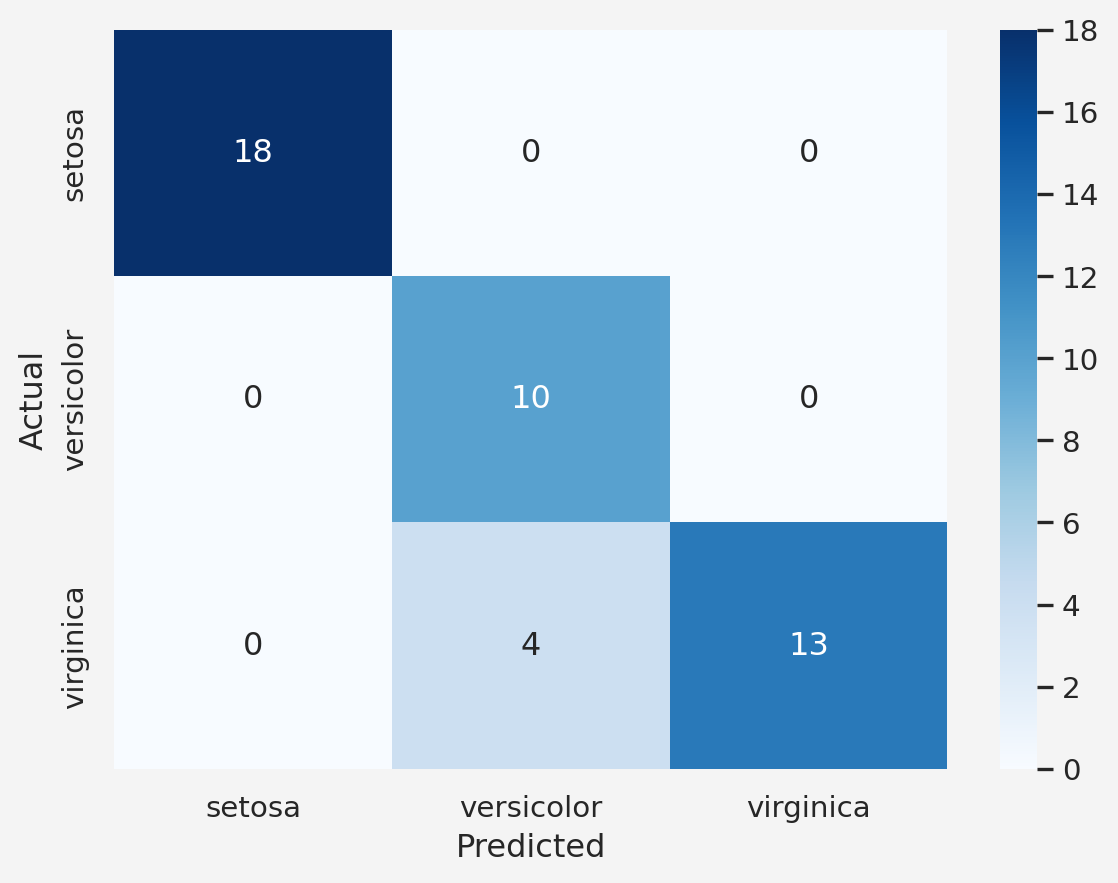
Multi-class classification is a critical aspect of many real-world applications, from medical diagnosis to image recognition and beyond. By understanding the strengths and limitations of different algorithms and strategies, we can choose the best approach for the task at hand. Whether using native multi-class models like decision trees or adapting binary models with OvR or OvO strategies, it’s essential to carefully consider the nature of the data, the number of classes, and computational constraints when building the models.
softmax function for multi-class classification.
Share on
You may also like
@online{islam2024,
author = {Islam, Rafiq},
title = {Classification: {Techniques} to Handle Multi-Class
Classification Problems},
date = {2024-10-17},
url = {https://mrislambd.github.io/dsandml/multiclass/},
langid = {en}
}

