
Bayesian Probabilistic Models for Classification
12 min
Tuesday, October 22, 2024
Random Forest is one of the most popular machine learning algorithms, known for its simplicity, versatility, and ability to perform both classification and regression tasks. It operates by constructing a multitude of decision trees during training and outputs the mode of the classes (for classification) or the mean prediction (for regression) of the individual trees.
Random Forest is an ensemble learning method that builds multiple decision trees and combines their predictions to obtain a more accurate and stable result. Each tree is built using a different random subset of the data, and at each node, a random subset of features is considered when splitting the data.
To understand Random Forest, we first need to recap how a decision tree works and then explore how Random Forest extends this idea.
A decision tree is a tree-structured model where each internal node represents a “test” on an attribute (e.g., whether the feature value is above or below a threshold), each branch represents the outcome of the test, and each leaf node represents a class label (classification) or a value (regression).
Mathematically, the decision tree makes decisions by minimizing the Gini Index or Entropy for classification tasks and minimizing the Mean Squared Error (MSE) for regression tasks.
Random Forest enhances decision trees by employing two key concepts:
The process for building a Random Forest can be summarized as follows:
For classification tasks, Random Forest works by constructing multiple decision trees, each built on a different subset of the data and a random subset of the features.
Given a dataset \(D = \{(x_1, y_1), (x_2, y_2), ..., (x_N, y_N)\}\), where \(x_i\) is a feature vector and \(y_i\) is the class label, Random Forest generates \(B\) decision trees \(T_1, T_2, ..., T_B\).
For each test point \(x\), each tree \(T_b\) gives a class prediction: \[ \hat{y}_b(x) = T_b(x) \] The final prediction is determined by majority voting: \[ \hat{y}(x) = \text{argmax}_k \sum_{b=1}^{B} I(\hat{y}_b(x) = k) \] where \(I(\cdot)\) is an indicator function that equals 1 if the condition is true and 0 otherwise.
In regression tasks, Random Forest builds trees that predict continuous values and averages the results.
Given a dataset \(D = \{(x_1, y_1), (x_2, y_2), ..., (x_N, y_N)\}\), where \(x_i\) is a feature vector and \(y_i\) is the continuous target variable, Random Forest generates \(B\) decision trees \(T_1, T_2, ..., T_B\).
For each test point \(x\), each tree \(T_b\) gives a predicted value: \[ \hat{y}_b(x) = T_b(x) \] The final prediction is the average of all the tree predictions: \[ \hat{y}(x) = \frac{1}{B} \sum_{b=1}^{B} \hat{y}_b(x) \]
Random Forest makes few assumptions about the data, making it highly flexible. Some assumptions include:
Here is a Python code example of how to implement Random Forest for both classification and regression using scikit-learn.
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestClassifier, RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, mean_squared_error
from sklearn.datasets import load_iris
# Classification Example: Iris dataset
iris = load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Initialize RandomForest Classifier
clf = RandomForestClassifier(n_estimators=100, random_state=42)
clf.fit(X_train, y_train)
# Predict and evaluate
y_pred = clf.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Classification Accuracy: {accuracy}")
# Regression Example: Boston Housing dataset
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
target = raw_df.values[1::2, 2]
X = data
y = target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Initialize RandomForest Regressor
reg = RandomForestRegressor(n_estimators=100, random_state=42)
reg.fit(X_train, y_train)
# Predict and evaluate
y_pred = reg.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
print(f"Regression Mean Squared Error: {mse}")Classification Accuracy: 1.0
Regression Mean Squared Error: 9.619662013157892Tuning the hyperparameters of a Random Forest can significantly improve its performance. Here are some important hyperparameters to consider:
n_estimators: This is the number of trees in the forest. Increasing this number usually improves performance but also increases computational cost.
max_depth: The maximum depth of each tree. Deeper trees can model more complex relationships, but they also increase the risk of overfitting.
min_samples_split: The minimum number of samples required to split an internal node. Higher values prevent the tree from becoming too specific (overfitting).
min_samples_leaf: The minimum number of samples required to be at a leaf node. Larger leaf sizes reduce model complexity and can help generalization.max_features: The number of features to consider when looking for the best split. Randomly selecting fewer features can reduce correlation between trees and improve generalization.
sqrt(number_of_features). For regression, max_features = number_of_features / 3 is often effective.bootstrap: Whether to use bootstrap samples when building trees. Set this to True for Random Forest (default) or False for extremely randomized trees (also known as ExtraTrees).To fine-tune the hyperparameters of a Random Forest, we can use GridSearchCV or RandomizedSearchCV in scikit-learn. Here’s an example of how to use GridSearchCV for tuning a Random Forest Classifier:
from sklearn.model_selection import GridSearchCV
param_grid = {
'n_estimators': [100, 200, 300],
'max_depth': [None, 10, 20, 30],
'min_samples_split': [2, 5, 10],
'min_samples_leaf': [1, 2, 4],
'max_features': ['sqrt', 'log2', None]
}
iris = load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Initialize Random Forest Classifier
clf = RandomForestClassifier(random_state=42)
# Perform grid search
grid_search = GridSearchCV(estimator=clf, param_grid=param_grid, cv=5, n_jobs=-1, verbose=0)
grid_search.fit(X_train, y_train)
# Best parameters from grid search
print("Best Hyperparameters:", grid_search.best_params_)
# Evaluate with best parameters
best_model = grid_search.best_estimator_
y_pred = best_model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy with Best Parameters: {accuracy}")Best Hyperparameters: {'max_depth': None, 'max_features': 'sqrt', 'min_samples_leaf': 1, 'min_samples_split': 2, 'n_estimators': 100}
Accuracy with Best Parameters: 1.0Using this technique, we can find the combination of hyperparameters that yields the best model performance.
One of the appealing aspects of Random Forest is that it provides a measure of feature importance, which indicates how much each feature contributes to the model’s predictions.
In Random Forest, feature importance is computed by measuring the average reduction in impurity (e.g., Gini impurity or MSE) brought by each feature across all trees. Features that lead to larger reductions are considered more important.
import matplotlib.pyplot as plt
import numpy as np
clf.fit(X_train,y_train)
# Get feature importance from the RandomForest model
importances = clf.feature_importances_
indices = np.argsort(importances)[::-1]
# Plot the feature importance
plt.figure(figsize=(10, 6))
plt.title("Feature Importance")
plt.bar(range(X.shape[1]), importances[indices], align="center")
plt.xticks(range(X.shape[1]), iris.feature_names, rotation=90)
plt.tight_layout()
plt.show()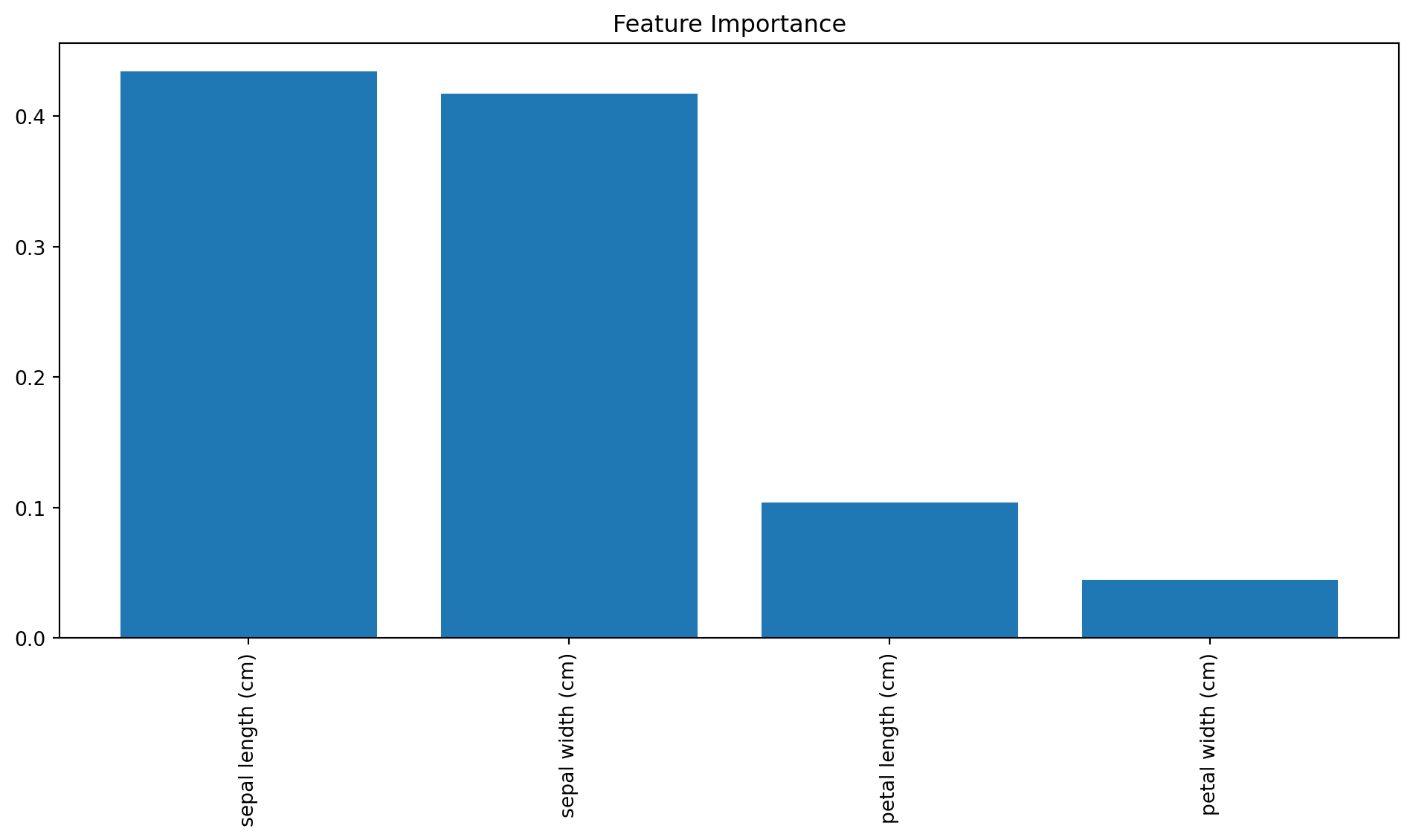
The bar chart is showing the relative importance of each feature, making it easier to understand which features have the most predictive power.
Random Forest uses Out-of-Bag (OOB) samples as an alternative to cross-validation. Since each tree is trained on a bootstrap sample, about one-third of the data is left out in each iteration. These “out-of-bag” samples can be used to estimate the model’s performance without the need for a separate validation set.
You can enable the out-of-bag error estimate by setting oob_score=True in the RandomForestClassifier or RandomForestRegressor.
clf = RandomForestClassifier(n_estimators=100, oob_score=True, random_state=42)
clf.fit(X_train, y_train)
# Access the OOB score
print(f"OOB Score: {clf.oob_score_}")OOB Score: 0.9428571428571428The OOB score is an unbiased estimate of the model’s performance, which is particularly useful when the dataset is small and splitting it further into training/validation sets might reduce training effectiveness.
For imbalanced classification tasks (where one class is much more frequent than the others), Random Forest may be biased toward predicting the majority class. Several techniques can help mitigate this issue:
clf = RandomForestClassifier(class_weight='balanced', random_state=42)
clf.fit(X_train, y_train)RandomForestClassifier(class_weight='balanced', random_state=42)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
RandomForestClassifier(class_weight='balanced', random_state=42)
from imblearn.over_sampling import SMOTE
sm = SMOTE(random_state=42)
X_resampled, y_resampled = sm.fit_resample(X_train, y_train)scikit-learn, set n_jobs=-1 to utilize all CPU cores for training.Random Forest is a highly flexible, non-parametric machine learning algorithm that can be used for both classification and regression tasks. Its ensemble-based approach reduces overfitting, improves predictive performance, and provides valuable insights like feature importance. Despite its many advantages, Random Forest is computationally intensive and may not be the best choice for real-time applications or datasets with extremely high dimensionality.
@online{islam2024,
author = {Islam, Rafiq},
title = {Ensemble {Methods:} {Random} {Forest} - {A} Detailed
Overview},
date = {2024-10-07},
url = {https://mrislambd.github.io/dsandml/randomforest/},
langid = {en}
}

