
Bayesian Probabilistic Models for Classification
12 min
Tuesday, October 22, 2024
For this data visualization project we use top 5 bank stock price data.
import pandas as pd
import yfinance as yf
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from mywebstyle import plot_style
plot_style('#f4f4f4')start = pd.to_datetime('2020-01-01')
end = pd.to_datetime('today')
df = yf.download(['WFC','BAC','JPM','C','GS'], start=start, end=end)
df.index = df.index.date
df.tail()[ 0% ][******************* 40% ] 2 of 5 completed[**********************60%**** ] 3 of 5 completed[**********************80%************* ] 4 of 5 completed[*********************100%***********************] 5 of 5 completed| Price | Close | High | ... | Open | Volume | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Ticker | BAC | C | GS | JPM | WFC | BAC | C | GS | JPM | WFC | ... | BAC | C | GS | JPM | WFC | BAC | C | GS | JPM | WFC |
| 2025-01-03 | 44.810001 | 71.000000 | 580.130005 | 242.029999 | 71.309998 | 44.849998 | 71.089996 | 582.140015 | 243.621784 | 71.419998 | ... | 44.750000 | 70.879997 | 581.000000 | 242.636865 | 70.349998 | 23455700 | 11342900 | 1422600 | 9491100 | 9152800 |
| 2025-01-06 | 45.400002 | 72.739998 | 583.390015 | 240.850006 | 72.029999 | 46.150002 | 73.989998 | 593.650024 | 245.690002 | 73.250000 | ... | 45.160000 | 72.230003 | 584.979980 | 243.699997 | 71.930000 | 30518500 | 19199700 | 2257000 | 9917800 | 15565600 |
| 2025-01-07 | 46.080002 | 73.680000 | 580.119995 | 243.169998 | 71.589996 | 46.650002 | 74.290001 | 588.280029 | 245.259995 | 73.129997 | ... | 46.279999 | 73.900002 | 587.109985 | 242.139999 | 72.970001 | 41111200 | 18309400 | 2021900 | 8753400 | 13522000 |
| 2025-01-08 | 46.209999 | 73.260002 | 580.020020 | 243.130005 | 71.570000 | 46.259998 | 73.470001 | 581.200012 | 244.250000 | 72.080002 | ... | 45.900002 | 73.449997 | 581.039978 | 242.750000 | 71.510002 | 40246000 | 13742800 | 1513400 | 8675300 | 16544700 |
| 2025-01-10 | 45.110001 | 71.400002 | 560.000000 | 239.869995 | 69.959999 | 46.049999 | 72.459999 | 576.000000 | 243.809998 | 70.910004 | ... | 46.000000 | 72.459999 | 576.250000 | 243.089996 | 70.900002 | 39048804 | 10557376 | 2241713 | 7745890 | 11267550 |
5 rows × 25 columns
Now we compute the maximum closing prices of all these 5 banks during this time period
df.xs(key='Close', axis=1, level='Price').max()Ticker
BAC 47.505741
C 73.680000
GS 605.570007
JPM 249.003983
WFC 77.349998
dtype: float64Now we compute the returns for each of the stock
# Retrieve the 'Close' prices for each ticker directly
close_prices = df.xs(key='Close', axis=1, level=0)
# Calculate the daily percentage change (returns) for all tickers
returns = close_prices.pct_change()
returns.index = pd.to_datetime(returns.index)
# Display the first few rows of returns
returns.head()| Ticker | BAC | C | GS | JPM | WFC |
|---|---|---|---|---|---|
| 2020-01-02 | NaN | NaN | NaN | NaN | NaN |
| 2020-01-03 | -0.020763 | -0.018835 | -0.011693 | -0.013196 | -0.006140 |
| 2020-01-06 | -0.001433 | -0.003137 | 0.010234 | -0.000795 | -0.005990 |
| 2020-01-07 | -0.006600 | -0.008685 | 0.006583 | -0.017001 | -0.008286 |
| 2020-01-08 | 0.010110 | 0.007618 | 0.009640 | 0.007801 | 0.003038 |
Let’s create a pairplot of the returns
sns.pairplot(returns[1:])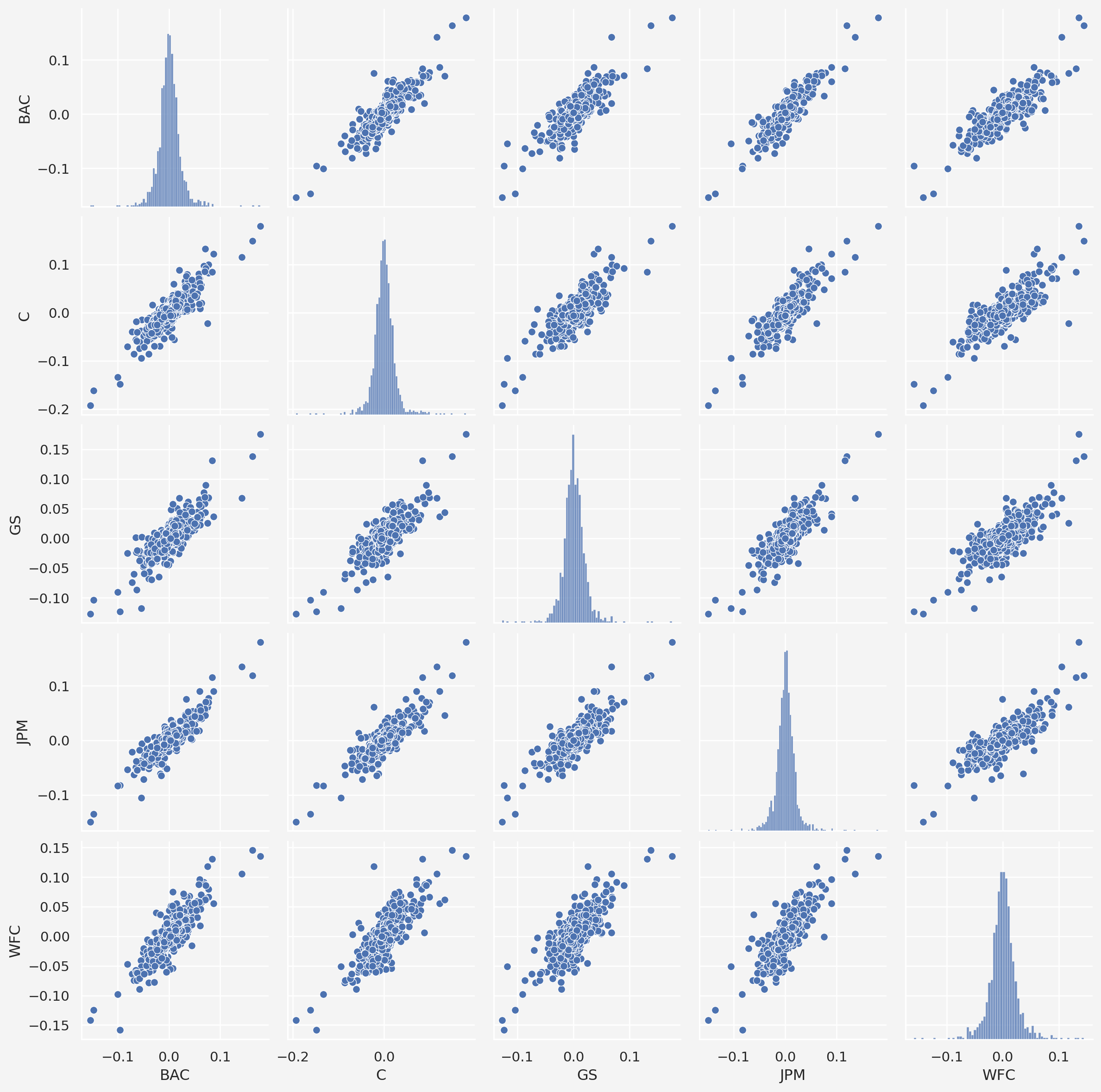
Now to check the maximum and minimum return and on what dates that happened
print('Minimum Return')
print(' ')
print(returns.idxmin())
print(' ')
print('Maximum Return')
print(' ')
print(returns.idxmax())Minimum Return
Ticker
BAC 2020-03-16
C 2020-03-16
GS 2020-03-16
JPM 2020-03-16
WFC 2020-03-12
dtype: datetime64[ns]
Maximum Return
Ticker
BAC 2020-03-13
C 2020-03-13
GS 2020-03-13
JPM 2020-03-13
WFC 2020-03-24
dtype: datetime64[ns]To find which bank is more risky we can simply check the standard deviations of the returns of each bank
returns.std()Ticker
BAC 0.022482
C 0.024632
GS 0.020837
JPM 0.020450
WFC 0.024600
dtype: float64It seems like CITI na groop has the maximum value in the standared deviations.
Now let’s check the distribution of Wells Fargo’s return in 2023
return_2023_wf = returns.loc['2023-01-01':'2023-12-31','WFC']
sns.displot(return_2023_wf, color='blue', bins=80, kde=True)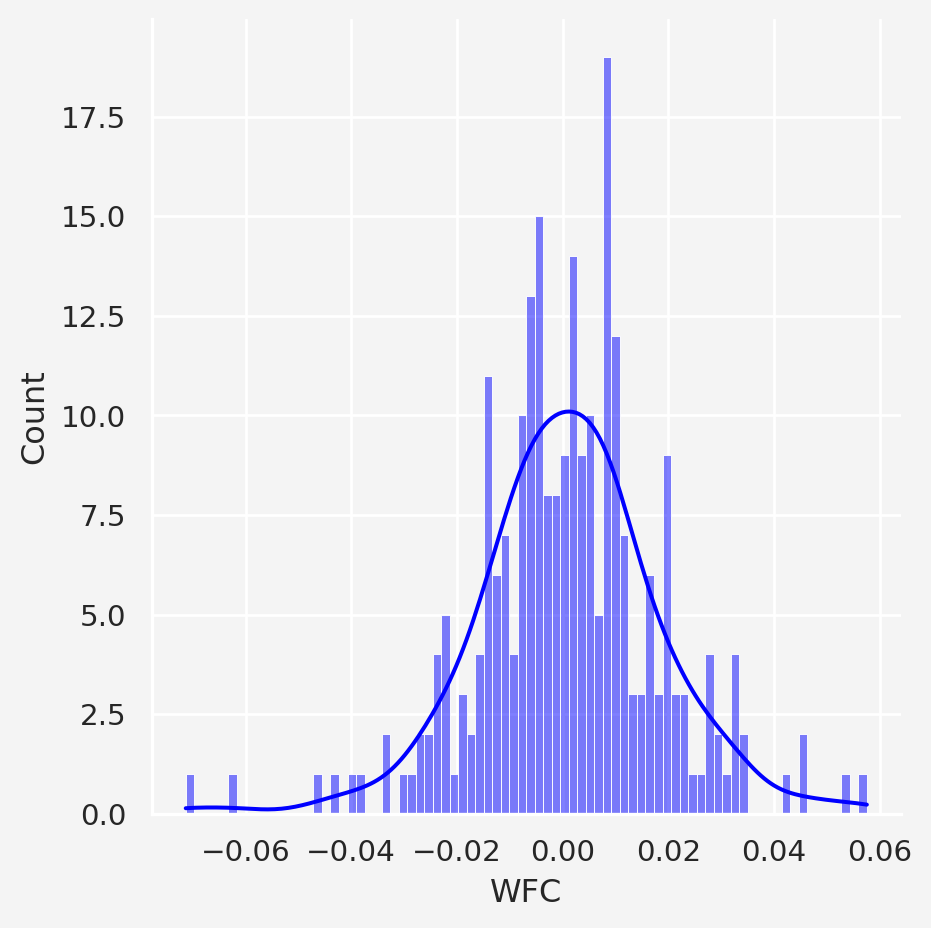
Next, we create the timeseries plot of the closing prices
df.xs(key='Close', axis=1, level='Price').plot(figsize=(9,5))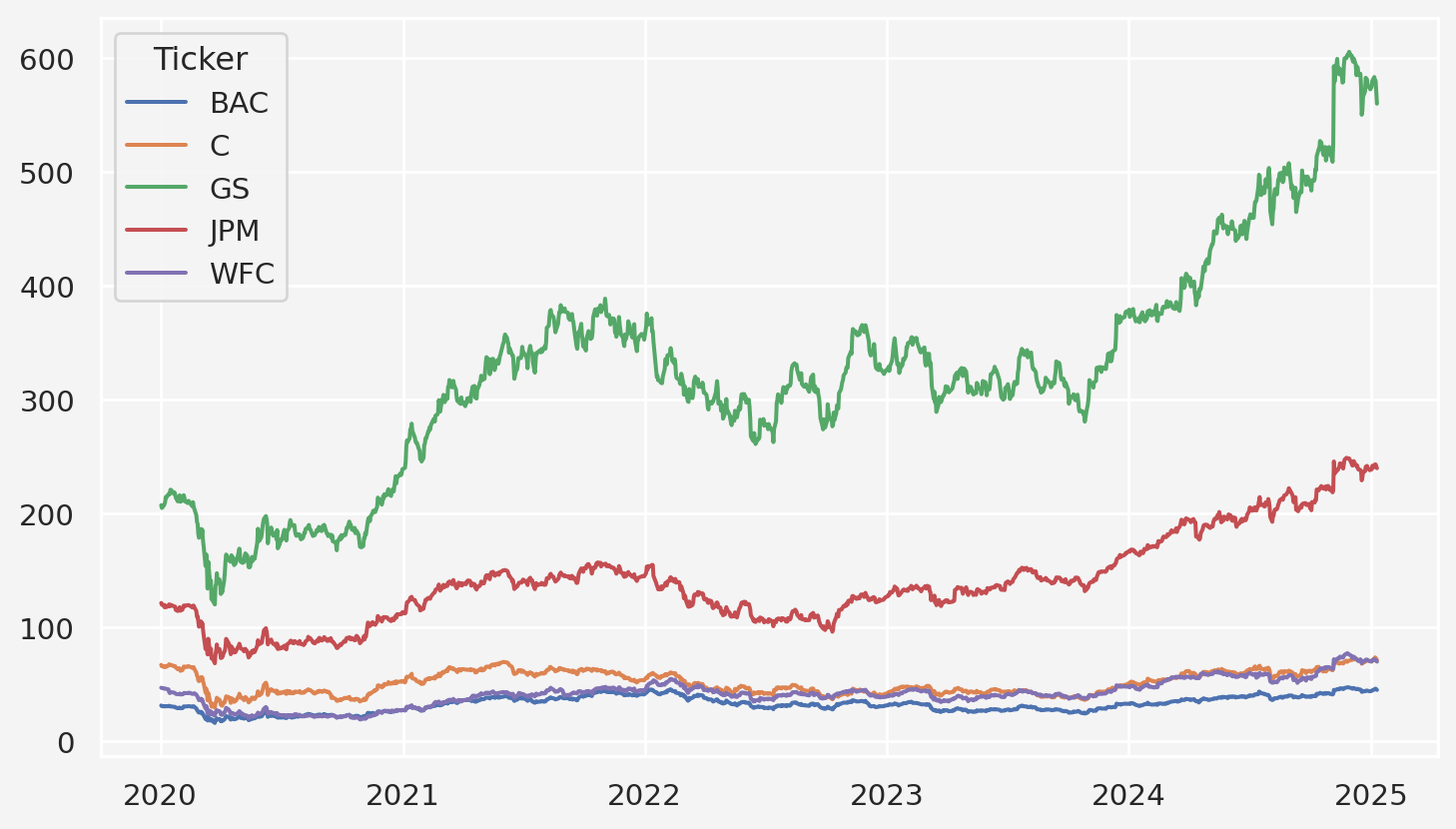
import plotly
import cufflinks as cf
cf.go_offline()
df.xs(key='Close', axis=1, level='Price').iplot()Next we plot moving average for Wells Fargo
wfc = df['Close']['WFC']
start_date = pd.to_datetime('2023-10-10').date()
end_date = pd.to_datetime('2024-10-20').date()
wfc.loc[start_date:end_date].rolling(window=30).mean().plot(
figsize=(9,5),label='30 Day Avg'
)
wfc.loc[start_date:end_date].plot(
label='WFC Close',figsize=(9,5)
)
plt.legend()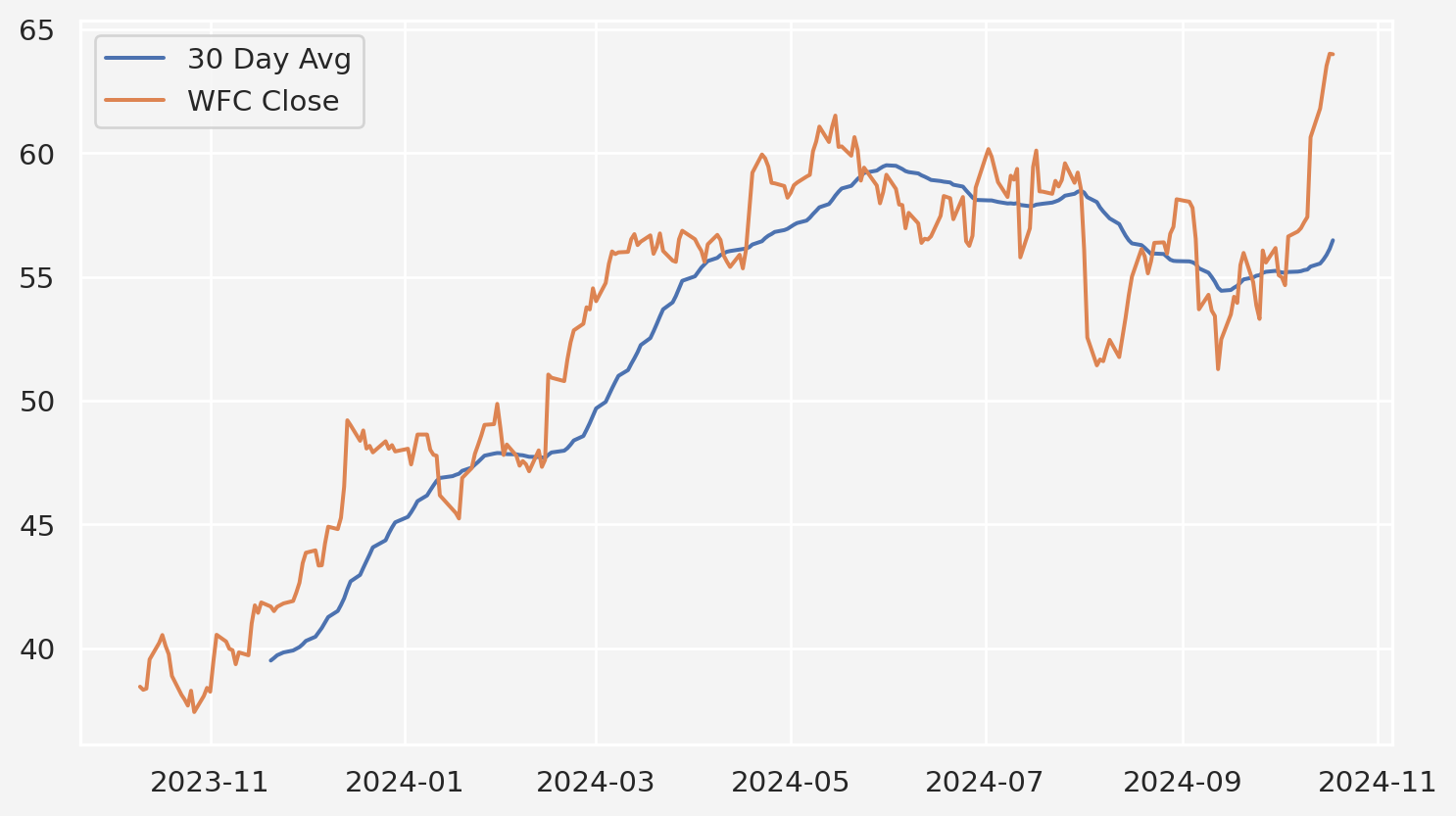
sns.heatmap(df.xs(key='Close', axis=1, level='Price').corr(), annot=True)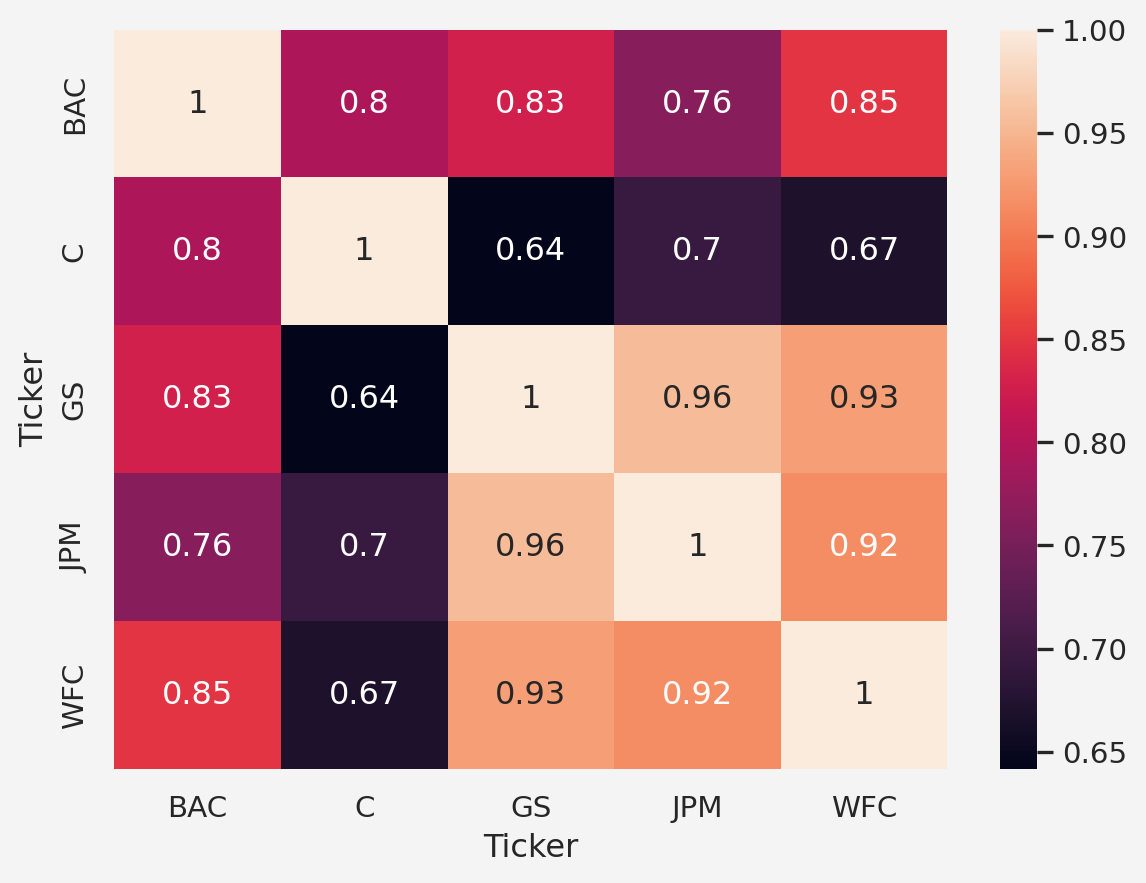
Candle PLot
wfc = df[['Open', 'High', 'Low', 'Close']].xs('WFC', level=1, axis=1)
# Define start and end dates
start_date = pd.to_datetime('2023-10-10').date()
end_date = pd.to_datetime('2024-10-20').date()
wfc_filtered = wfc.loc[start_date:end_date]
wfc_filtered.iplot(kind='candle')Bollinger Plot
wfc_filtered['Close'].ta_plot(study='boll')Share on
@online{islam2024,
author = {Islam, Rafiq},
title = {Data {Visualization}},
date = {2024-11-08},
url = {https://mrislambd.github.io/dsandml/dataviz/},
langid = {en}
}

